
Unlock Your Business Potential with Expert Tech Solutions









Why Choose Our Software Development Company?
200+
Skilled Professionals
150+
Proud Projects
50+
Clients globally

Take your business to the new heights with Experts.
Driving Growth for Enterprises and SMEs Alike





































Exploring Infinite Horizons of Technology
L’azurde
Emaar
GSK Haleon
Zbooni
Madame sum
Juicy Couture

What Customers say about us

Rizwan Rajpoot
Chief Digital Officer, L'azurde

Ramy Assaf
CEO and Co-Founder - Zbooni

Kirti Bansal
Staples
Team Emaar LMS
Chris Smith
VP of Technology
Valuable Feedback that Matters
%202.png)
Collaborations and Partnerships to Help You Scale







Technologies we use for clients




















































Gain valuable insights

7 Steps to Build a Generative AI Solution from Scratch in 2024
Generative AI is a revolutionary advancement in the tech world that has taken businesses and decision-makers by storm. With everyone using AI models like ChatGPT and Stable Diffusion to speed up development processes, it's safe to say that generative AI is here to stay.
Jasper, one of the successful generative AI tools, has raised $125 million at a valuation of $1.5 billion by assisting businesses with copywriting. Similarly, Stability AI has made $101 million with a valuation of $1 billion. But the most significant achievement is that of OpenAI, which generated over $1 billion from Microsoft at a valuation of $25 billion in 2019.
Clearly, the scope for generative AI solutions is broadening. Read on to learn everything you need to know about how to build a generative AI solution from scratch.
What is Generative AI?
Back in the 1950s, researchers first explored the basic principles of artificial intelligence and generative AI. The initial focus was on simple neural networks and rule-based models to mimic human decision-making.
On the surface, generative AI is an exciting new development where deep learning algorithms are used to create content, graphics, music, and more. Large datasets are used as input for deep learning algorithms that can generate unique content. What makes generative AI special is its ability to generate entirely new and unique outputs, unlike traditional AI which only delivers pre-programmed outputs.
When trained, the AI algorithms learn patterns from given inputs, store them, and utilize them to create unique content for similar inputs. Even though it looks easy, generative AI becomes quite complicated when you dig deeper. For instance, there are various components like transformers, generative adversarial networks (GANs), and variational auto-encoders behind the functionality of generative AI.
Examples of transformers include ChatGPT, LaMDA, Wu-Dao, and GPT-3. Transformers are trained to process natural language and images, as well as learn classification tasks and generate texts. These techniques are designed to mimic cognitive attention and understand the difference between varying inputs.
What Can Generative AI Do?
Generative AI is helping businesses worldwide by generating content in the form of text, images, and videos. This means voice-over and background music in videos are not a problem anymore. Generative AI is also used in data augmentation to boost the accuracy of predictive machine-learning models. As a result, retailers can offer highly personalized experiences to customers.
The following are some of the diverse application areas of generative AI across various industries:
Art and Creativity
The new, state-of-the-art algorithms of generative AI enable you to convert any ordinary picture into an art piece. You can guide the AI tool to add your unique style, features, and other favorite items. Even when you provide the generative AI tool with a rough sketch of the image you want to create, it generates photorealistic masterpieces that go beyond your expectations. Not only that, but the AI can also imitate specific styles of a given human artist, which allows you to create art like never before.
Content Generation
When it comes to automating content creation, you don’t need to look further than generative AI. It has provided marketers with the ideal solution to save time and resources. With automated content generation, you can achieve faster time-to-market and create a variety of campaigns. For instance, you can create social media posts and blog articles, and even design email campaigns.
AI tools like ChatGPT, Jasper, Copy.ai, and Writesonic have accelerated the process of content generation. In some cases, marketers can personalize and refine drafts generated by AI models. Not only that but generative AI can also be used to update existing content with valuable inputs and improvements.
Natural Language Processing
Generative AI is commonly used in natural language processing to create social media posts and news articles. Various natural language processing techniques are used to generate the text for such posts. These techniques includes transforming raw characters like words, letters, and punctuation into sentences. The resulting entities and actions are represented in the form of vectors through multiple encoding mechanisms.
Image Synthesis
Today’s businesses want to represent their products and services with realistic graphics and lifelike images. Here, AI algorithms assist businesses with accurate image synthesis. You can eliminate misleading aspects from your images and fill in the missing elements to portray your products in the best way.
Medical Imaging
That’s not all - AI tools can also convert low-resolution images into high-resolution images, making them look like they were captured by professional photographers. With generative AI by your side, your images are transformed into clear and detailed masterpieces. This is particularly useful in medical imaging analysis, where accuracy is of utmost importance.
Generative AI is used in medical imaging for specific tasks like image segmentation, anomaly detection, and prediction of patient outcomes.
Anomaly Detection
Business owners need to go through large amounts of data to understand patterns in order to make informed decisions. In this case, generative AI helps detect anomalies in a series of data. Assuming a certain range of data based on historical trends, AI can point out values that fall outside that threshold and happen less frequently.
How Generative AI is Changing Industries
The world knows generative AI as a buzzword because of its impact on different industries. It has quickly transformed business operations and is creating new opportunities across the board. Apart from creating novel, unique content and making way for innovations, generative AI is changing the way processes are carried out.
Here are some examples of how generative AI is transforming various sectors:
Entertainment and Media
Two of the many benefits of generative AI are democratized content creation and simplified management. In the entertainment industry, AI helps accelerate research tasks and allows filmmakers to improve the efficiency of their post-production operations. The data processing power of AI makes video libraries more searchable, making life easier for broadcasters. For this reason, the market size of generative AI is expected to grow to $12,077 Million in 2032 at a CAGR of 26.7%
Healthcare
Whether it is medical diagnosis, imaging, or analysis of a large number of patient records, AI is always good news for the healthcare industry. You can now leverage AI-based disease prediction and diagnosis to improve healthcare operations. Generative AI monitors various factors like lifestyle risk factors, medical imaging, patient health data, environmental factors, and genetic data to provide accurate results. Moreover, statistics show that 27.5 percent of health systems currently use conversational AI, with a further 72.5 percent considering it for future use.
Marketing and Advertising
Until a few years ago, marketing and advertising agencies required graphic designers and content creators to create their campaigns. But now, AI is being used by 53% of IT companies for marketing and advertising. With generative AI, this process is a matter of a few prompts. You can prompt AI tools to create unique and original graphics for blog posts, social media posts, and more.
Gaming
Game development is a complex and time-consuming process that involves various tasks. Like other industries, generative AI becomes useful in game development by automating complex tasks. These include creating assets, levels, and generating dialogues. By utilizing generative AI to handle these tasks, game developers are able to unlock creativity and use the extra time to work on the strategic aspects of their development cycle. Generative AI in the gaming sector is expected to achieve the highest market value with a valuation of $7,105 Million by 2032.
Manufacturing and Design
Now here’s an industry that focuses on optimized production and quality controls along with great customer service. By processing raw data and helping in the production of valuable products, generative AI significantly improves manufacture and design operations. According to Gartner, by 2025, generative AI will account for 10% of all data produced, up from less than 1% today. It helps enhance customer service, streamline production processes, and also improves quality control procedures.
The Right Tech Stack to Build a Generative AI Solution
Before getting into the process of building your own generative AI solution, you need to know the right tools and technologies to use. The following is a comprehensive list of the tech stack you will need to use:
7 Steps to Build a Generative AI Solution from Scratch
In order to build a generative AI solution, you need to develop a comprehensive understanding of its purpose and the problem it will solve. The process involves creating and training AI models to generate unique outputs depending on varying inputs.

As today’s generative AI solutions are capable of optimizing and improving operations, building a satisfactory solution requires you to follow a series of steps.
Problem Identification
Since you are dealing with a lot of computing power in generative AI, you need to be sure that they are designed to solve the right problem. The first step in building your generative AI solution from scratch is to identify a set of problems to solve. For instance, marketing agencies need various types of content for their blog and social media platforms. In this case, your AI solution needs to be built around natural language processing, neural networks, and generative pre-trained transformers. In other cases such as video and audio generation, you will need to adopt a different approach.
Data Collection
Data collection is one of the important steps in the prototyping phase of generative AI development. Since the training of your generative AI solution depends on data, you need to consider certain technical details. These include:
- Identifying the right data sources
- Ensuring that high quality, relevant, and diverse data is collected
- Labeling the data if needed using crowdsourcing, semi-supervised learning, or active learning
- Preprocessing data through data augmentation, tokenization, or normalization before it is fed to the AI model
- Splitting the data into separate categories for training, validation, and testing
- Storing the data in data warehouses, distributed file systems, or cloud storage depending on the scenario.
Model Selection
Based on the defined problem that the AI solution is intended to solve, you need to select the right model and tech stack to be used in the development. To be able to choose the right model, you need to categorize the problem and determine the right algorithms to solve it.
For instance, if you’re working with input categorization, you need to select the supervised learning model. For imaging systems that can differentiate objects from images, you can work with OpenCV. On the other hand, you can also use Jupyter Notebook to allow seamless collaborations between machine learning engineers, developers, and data scientists.
Architecture Design
In order to ensure that your generative AI solution can process large amounts of data and handle high traffic, you need to base it on a robust and scalable architecture. The common purpose of all generative AI solutions is to maintain high performance, reliability, and availability in all situations. The best practices to build the right architecture are as follows:
- Break down the AI solution into small, manageable components through microservices architecture
- Adopt a modular design where each module performs its specific function
- Incorporate message queues to efficiently manage communication between different components of the AI solution
- Implement load balancing to ensure equal traffic distribution across multiple servers and get peak performance
- Implement caching to reduce backend requests by storing frequently accessed data
- Configure hyperparameters of the generative AI model to set number of layers, learning rate, batch size, regularization techniques, dropout rate, etc.
Training and Validation
In the training phase, you feed the AI model with datasets you previously collected and categorized. With these datasets, the generative AI model learns patterns that are later used to solve problems and create content. In order to train generative AI models, you need to use self-supervised learning and semi-supervised machine learning methods. Although the process is machine dominant, you need to add the human touch to fine-tune and set the AI model’s accuracy and align it with your business objectives.
Deployment and Integration
While deploying your AI solution, you need to be sure of its reliability, scalability, and maintainability. This is particularly important to eliminate errors and failures and ensure the smooth functioning of your generative AI solution. Here’s what you need to consider in the deployment and integration phase:
- Choose the right deployment environment by setting up on-premise infrastructure, cloud computing systems, or hybrid solutions depending on the requirements.
- Implement the right hardware and software for installing operating systems, setting up databases, and configuring servers.
- Set up dependencies like libraries, frameworks, and packages required to run your AI solution.
- Use tools like Jenkins, Travis CI, or GitLab to set up continuous integration and deployment (CI/CD) pipelines.
Monitoring and Maintenance
The last step of the process holds equal significance. Upon deployment, you need to constantly provide support and maintenance while evaluating how the AI solution performs in real-life use cases. The key is to identify bottlenecks and failures in order to fix and improve the solution. Upon further testing, you can refine your AI solution by studying user feedback and performance benchmarks.
Pro Tips for Crafting Effective Generative AI Solutions
Even when you follow the best practices to build your AI solution, there are always going to be some unexpected issues and challenges along the way. Based on research in the field of generative AI, here are a few pro tips that can be helpful.
- Apart from identifying a problem to solve, you should also identify specific business processes that can be enhanced by using generative AI. Focus on small changes with meaningful outcomes.
- Ensure data protection to provide users the confidence to use your generative AI solution and stay compliant with international regulations. Use data encryption to reduce risks of data leaks.
- Instead of spending big bucks on training AI software like ChatGPT, you should build smaller, more targeted AI models. These can be trained to solve business problems unlike ChatGPT.
- Since the quality of data matters, your focus should be on preparing the data for training the AI model. Try to eliminate under-generalization and bias.
- Regardless of how well you train generative AI, it can never be perfect. Therefore, you need to inform your users about the limitations of your AI solution.
Costs of Generative AI Solution Development
Depending on the type, complexity, and size of the application you are trying to build, generative AI development becomes quite a costly process. This means you can expect a bill between $10,000 and $500,000. The most notable costs include training the AI model and deploying it. The software cost itself is between $35,000 to $120,000, while maintenance costs can go beyond $320,000 per year.
That’s not all, you also need to invest in specialized hardware and cloud storage to get the right computing power and storage capacity. Depending on the complexity of your solution, this can cost you between $100 and $15,000 a month.
FAQs
Can I make my own generative AI?
You can create your own generative AI by adopting, modifying, and building the models you require. However, the process is quite complex and you need an increasing number of resources as you continue building your generative AI. You also need to have technical expertise in the fields of natural language processing, machine learning, and computer vision.
How do I start generative AI?
First of all, you need to understand the different generative AI models available in the market. You should consider the unique features and applications of GANs, autoregressive models, and VAEs. You need to gather and prepare the data you want to work with and choose the type of AI architecture to use. Then you need to train your AI model and evaluate, optimize, and test it in a real-world environment.
Does generative AI use NLP?
Yes, generative AI leverages natural language processing to create new outputs or content for each input. The use of NLP means that you can also generate all types of content including text, images, audio, and video.
Is generative AI free to use?
There are free versions of generative AI tools like ChatGPT 3.0 and DALL-E 2. These are great for beginners who want to try generating content using AI. AI tools by OpenAI allow you to generate content by simply creating an account on their website and entering your prompts in the search bar.
Key Takeaways
In the era of artificial intelligence, businesses are being driven by generative tools that enhance operational efficiency and also help target the right customers. With businesses adopting generative AI solutions, there really is no limit to what can be achieved in the near future. We can expect unprecedented business growth with the help of efficient processes, ease of use, and the automation of complex operations. Based on the steps discussed in this blog, you can build your generative AI solution and embrace its transformative power in your business use cases.

7 Computer Vision Use Cases in E-Commerce for 2024
Modern technologies are transforming the way people shop online by influencing their purchase decisions. With 88% of customers attributing product images to a great shopping experience, the use cases of computer vision in e-commerce continue to grow.
Computer vision allows retailers to provide buyers with new ways to search for products. Simultaneously, sellers can leverage automated inventory management, quality control, and much more. The technology is a form of artificial intelligence and works by deriving meaning from digital images just like humans - sometimes even better. It replicates the way we visualize products and performs image recognition, distinction, and classification using AI.
In this post, we discuss 7 computer vision use cases in e-commerce. Read on to find out how cutting-edge AI technology is reshaping the digital landscape.
The Role of Computer Vision in E-commerce
Customer expectations are changing, and so are retail businesses. The industry now recognizes the need for displaying interactive content in the form of product images and descriptions to improve the customer experience.
Computer vision is mostly dependent on high-quality images uploaded by sellers and customers on the internet. Digital marketplaces use it to match the items a customer searches for - and quickly provide them with the right results. Not only that, but computer vision also helps verify the uploaded images to determine the quality of the product in question. As a result, shoppers can feel secure knowing that the platform is offering the right products.
The use of AI makes product search a breeze as you can display images dynamically to deliver an exceptional retail experience. You can automate repetitive tasks and save money. As AI enables computers to see and perceive images like humans, online shopping will become much more convenient in 2024. It improves engagement and you can have more loyal customers.
Use Cases of Computer Vision in E-Commerce
Visual Search Capabilities
Up until a few years ago, online shopping started with a text-based search query. Users had to go through a lot of products to find what they wanted. However, the introduction of AI technology has changed that. Visual search is one of the biggest leaps we have seen thanks to computer vision in e-commerce. It is an entirely new way of searching for products online.
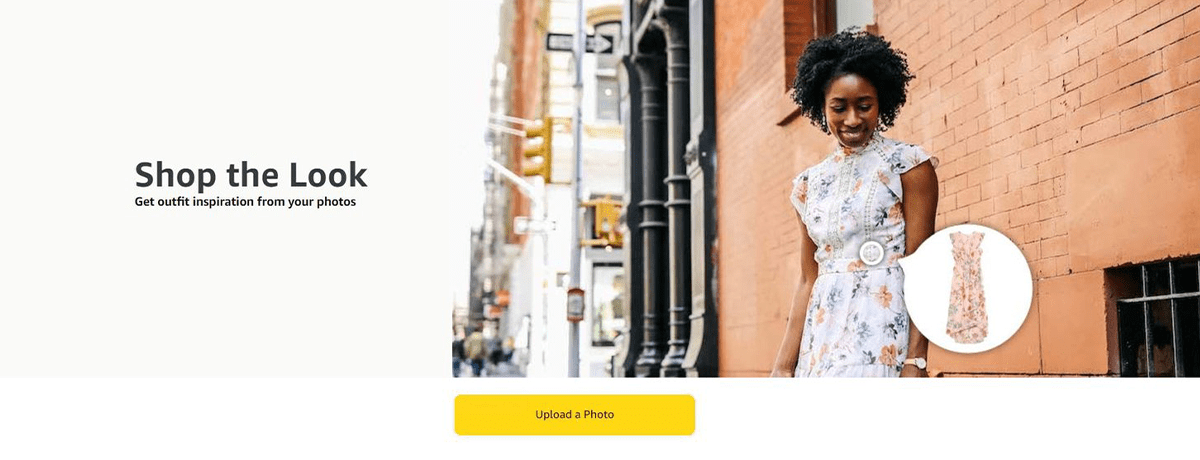
Amazon’s Shop the Look interface
Users can simply upload a photo of the product they want to buy, and AI brings up all the relevant items in the store. A survey showed that 62% of Gen Z and Millenial customers in the UK and US want visual search capabilities in their online shopping journeys.
Even though it might not have made its way into all e-commerce stores yet, those who have experienced it do vouch for it. Amazon and eBay are two big names that leverage computer vision for visual search. Amazon’s StyleSnap provides the best-matched results for products when users upload a photo, and eBay customers can also search among 1.1 billion products using photos instead of text-based queries.
Automated Inventory Management
Inventory management is something that every retailer wants to ace. However, the days of manual inventory counts and stock management are over. Since your customers expect swift delivery within a day, you need to be on top of your inventory game at all times.
Here, computer vision helps you meet customer demands and maximize your sales. It allows you to analyze visual data from your inventory and order stock accordingly. The visual analysis helps you stay ahead of the curve by maintaining a steady stock level. Whenever a new order is placed, you don’t have to keep your customer waiting. You don’t have to worry about running out of stock or overstocking your warehouse.
Automated inventory management with computer vision helps create a seamless shopping journey. Neither do you miss any sales opportunities, nor do your customers face any delays. Automating the inventory management process also streamlines replenishment operations to ensure that popular products are always in stock.
Augmented Reality Shopping
In retail, augmented reality shopping has taken the e-commerce experience to a whole new level. AR with computer vision goes beyond virtual try-on experiences to completely transform the way customers view their products.
In augmented reality, computer vision recognizes objects in visual data through object detection. It uses object tracking to understand movements and count objects, and Simultaneous localization and mapping (SLAM) to localize an AI bot on a map. These complex processes collectively make up the immersive shopping experience we see on AR shopping apps.

Features like augmented product displays and virtual showrooms make it easier for customers to understand what they are paying for. They can explore the product in detail, compare the different options, and even take a virtual walk-through of the store.
Computer vision in AR also provides you with valuable insights into customers’ preferences. By incorporating AR into your e-commerce store, you can create a dynamic shopping environment and enhance the customer experience.
Quality Control and Inspection
Businesses in the retail industry compete on various fronts, but nothing beats quality products. When it comes to fashion, electronics, or other products that are assessed by visual characteristics, you need to ensure quality standards.
Thankfully, quality control is another use case of computer vision in e-commerce. Here, computer vision is used for visual inspection of products at different stages of the supply chain. You can incorporate it at the manufacturing phase, the distribution phase, and when the product reaches your store shelves.
The quality control process involves computer vision algorithms that detect imperfections or defects in products. They perform visual inspection and compare products to a set standard to determine whether they meet the quality requirements.
Incorporating computer vision for quality control allows you to improve customer satisfaction and lower your return rates. When customers get the same quality of products from your brand, they begin to trust it and become loyal customers.
Customer Behavior Analysis
Moving on, here is another important use case of computer vision in e-commerce. In retail, customer behavior analysis is the key to improving the customer experience. The more you know about your customer's preferences, the better you can assist them.
In this use case, computer vision analyzes customer data to provide you with valuable insights to understand their shopping behavior. Integrating this technology into your e-commerce platform allows you to track customer activity across the store and understand how they interact with each aspect of your store.
This includes product pages, the checkout page, the homepage, and more. However, computer vision is not limited to your online store only. In the physical store, it uses heat map technology to detect real-time movements and assign colors based on traffic volume. This helps retailers understand which sections of the store are more crowded and how they can optimize product placement, store layout, and more.
Shipment and Logistics Optimization
The last stages of the supply chain are the most crucial for retailers, as they can make or break customer trust. In shipment and logistics, computer vision is used to extract data from package labels and detect damages to parcels. It helps quickly identify and sort parcels depending on your business constraints.
The AI system can sort by size, destination address, shape, or category of products. You can track packages in real-time within your store and while they are on their way to the customer. Real-time tracking with computer vision helps eliminate instances of misplaced items.
Moreover, the technology helps you automate and simplify various operations in the dispatching and shipment of products. On a larger scale, computer vision can monitor activities on ports to detect suspicious activities that lead to misplaced parcels.
Product Recommendations
Product recommendations are one of the best ways to engage customers online. Every time a shopper visits your e-commerce store, they see products on the homepage before they even begin their search. Computer vision makes this possible by analyzing the users’ search history, items they’ve previously purchased, and similar data from millions of other users.
According to a survey, 91% of customers are more likely to shop with brands that remember their shopping history and provide relevant suggestions.
In the e-commerce use case, computer vision algorithms process large volumes of user data to provide accurate personalized recommendations. As a result, your customers feel that your brand takes care of their preferences and displays highly relevant content. Finding the right products on the homepage of an online store also means that customers have to spend less time searching.
With the help of pattern-matching algorithms, computer vision analyzes customers’ online journeys to determine the key areas where they might need helpful suggestions. Sometimes, users simply browse through your store without the intention of buying anything. Here, you can convert them into customers with the right product recommendations. Not only that, but these kinds of suggestions can also help upsell and cross-sell slow-moving items.
Benefits of Computer Vision in E-Commerce
Beyond the common use cases, computer vision exceeds expectations to deliver an enhanced customer experience. Starting from product classification based on visual attributes, and going towards predictive analytics, the technology has transformed e-commerce for the better.
- Brand detection
Computer vision utilizes advanced algorithms and machine-learning techniques to identify retail brands in images and videos.
- Effective market analysis
With the help of visual detection, brands can understand the popularity of a given product in the market and restrategize.
- Predictive Analytics
The technology analyzes customer behaviors and preferences to create and display personalized product recommendations.
- Enhanced customer experience
Your customers can find their products by uploading images and don’t have to go through a long list of products to find what they need.
- Operational efficiency
Computer vision helps identify efficient routes for the supply chain and makes it easier for you to manage your e-commerce operations.
- Security
With fraud detection capabilities, computer vision helps eliminate the risk of misplaced items, unscanned items, and employee theft.
Embracing the Future of E-Commerce
Computer vision and the other subsets of AI have quickly become a necessity in the e-commerce landscape. With customers expecting a smooth omnichannel shopping experience, the applications of computer vision seem to be increasing quickly. In the retail sector, the technology has already automated checkouts, monitored queues, and analyzed foot traffic.
The buzzing technology has come out of the research phase to become a highly useful e-commerce tool. While there is no comparison between an AI-based system and a manual process, the benefits of computer vision in e-commerce retailers are too obvious to ignore.

The Ultimate Guide to AI App Development Using Generative AI
App development has come a long way in recent years. As AI pushes the boundaries of innovation in software development, generative AI app development has become one of today's biggest buzzwords. In fact, it has the potential to boost business profits by up to $4.4 trillion a year.
AI changes how we conceive and build our apps by unlocking unimaginable possibilities. Using large language models, developers can create intuitive in-app experiences. You also get to personalize user experiences with enhanced creativity.
Read on to find out how the ground-breaking AI technology enhances app development.
How Generative AI differs from other AI technologies
AI has been here for quite some time in the form of machine learning and computer vision. However, these technologies are limited to analyzing and classifying datasets. Generative AI is capable of creating new content based on existing data. This can be in code, text, images, video, music, and more.
Generative AI is currently being used for the development of innovative apps in different industries.
Generative AI can be used to generate code for mobile apps, which can save developers a lot of time and effort. For example, DhiWise has introduced the new feature “WiseGPT” which analyzes the entire codebase to produce personalized production-ready code without writing prompts. The other is the “GitHub Copilot” tool that can generate code snippets and even entire functions based on natural language prompts.
The Role of Generative AI in App Development
Generative AI offers an unparalleled ability to test apps for bugs and errors. AI-based systems not only identify security risks but they can also be used to write code for a wide range of applications.
Enhancing user experience with Generative AI
When it comes to online websites and applications, user experience is crucial. You need to have seamless transitions between different responsive, user-friendly pages. Here, generative AI can automate repetitive tasks in app development.
As a result, it can solve problems without human input. You get an exceptional user experience with a bug-free application that doesn’t require any expert developer insights. That said, the effectiveness of generative AI apps depends on how well you train them.
Personalization and customization through AI
Personalized content is the way to go in the modern world. And nothing creates personalized and customized content like generative AI. By analyzing user history including search and preferences, AI creates personalized recommendations. This enhances the user experience by creating more opportunities for customer engagement.
Generating content and creative elements automatically
When humans work in cross-functional teams, the output is great. Imagine AI doing the same, except with much higher efficiency. Generative AI raises the bar of creativity and innovation. It produces content that would take us too much time to create. Plus, we would need to use various methods and tools to come close.
Automated content generation takes app development to a whole new level. You can now uncover new concepts before even creating the application. Using novel patterns, styles, and combinations, AI allows you to create perfection.
Improving app development with predictive models
Predictive analytics is a field of AI that allows developers to optimize app functionalities. By factoring in the time, effort, and cost of app development, it provides a clear pathway. You can easily identify potential risks and hurdles. It also allows you to eliminate bottlenecks to enhance the functionality of your application. These measures reduce the likelihood of issues arising during the development life cycle.
Getting Started with Generative AI App Development
Before getting started with generative AI app development, you need to know its basics. The best practices allow you to be more productive in the process by making it smooth. Whether it's your first time or you’ve been working with AI, here are the steps for app development with generative AI:
Gather high-quality data
No matter how powerful an AI tool is, it still needs to be trained using existing data. The quality of this data determines how well generative AI will perform. Therefore, the first step is to gather error-free and well-structured data. Make sure it does not have any inconsistencies or biases. And of course, it should be relevant.
Training your AI model using high-quality data yields accurate outputs. This makes app development with generative AI worth your while. And your app performs the intended functions with maximum effectiveness.
Choose the right tools and frameworks
Choosing the right algorithms and AI models is among the critical aspects of using generative AI. You need to ensure that you choose the right one based on your specific use case. For example, if you want to generate natural language texts, you can work with algorithms like GPT-4. But if you want images as output, you need a deep learning model like GANs. If you make the right decision, your generative AI app will perform effectively and yield quality outputs.
Understand the data requirements for training AI models
Moving on, you need to ensure that your AI model operates at maximum efficiency. For this, technical know-how of data requirements is crucial. You can adjust the AI’s learning rate, batch size, and epochs, and even regularize it. Here,
- Batch size means how much data it can process at a time.
- Epochs mean the number of times it learns from the data.
- Regularizing means you can prevent it from overthinking or overprocessing data.
Fine-tuning your AI models results in high efficiency of the application.
Building Your First Generative AI App
Building a generative AI app is a complex process that requires you to follow a unique set of steps. Here’s how you can get started with your first app:

Selecting and preparing your dataset
The process of developing an AI app starts with data. You need to identify the right sources to extract the datasets you’ll be using. This can be done using databases, web scraping, sensor outputs, and APIs depending on your requirements. This is a crucial step as the quality of the data directly affects the performance of your AI model.
Apart from data sourcing, you also need to pay attention to data diversity. The more diverse your data, the better the AI will perform. Its outputs will be more unique if you train it with different scenarios, modalities, and environments.
Training your Generative AI model
This is the step where your efforts shine through. Using the data you’ve gathered and cleaned, you need to train your generative AI model. You’ll be using deep learning and neural networks to feed the prepared data to the AI. It then learns to identify and emulate data patterns.
When the initial model is sufficiently trained, you can proceed to fine-tune the AI. Here, you can go deeper into specific tasks to generate the desired outputs. For instance, you can fine-tune your AI model to create poetry. You’ll have to train it on an extensive dataset of poetic content. Here, you can also deploy techniques like differential learning rates. This process takes different layers of the AI through different learning rates.
Integrate the AI model into your app
Once your AI model is ready to go, the next step is to integrate it into your app. For this, you need to develop APIs or connectors. APIs act as a bridge that fills the gap between your app and the generative AI model. Then, you need to design workflows to ensure that the data generated by AI is integrated into your existing processes. Frameworks like FastAPI and Flask are commonly used to deploy APIs with AI models.
Testing and optimizing app performance
Using real-world conditions and comprehensive testing techniques, you need to test the AI app performance. This step helps you determine whether your training in the AI model has been fruitful.
Testing an AI model for performance requires validation and data metrics. With metrics like the ROC curve, AUC score, and error analysis, you need to assess the quality of the AI model's outputs. Moreover, you can compare the outputs with benchmark models to see where your AI model falls behind in terms of accuracy and performance.
Advanced Techniques in Generative AI App Development
Improving Model Accuracy and Efficiency
An AI model is like a work in progress. You can keep making changes and updates to tweak its performance. In the case of app development, you can improve your AI model with the following techniques:
- Retrain the model on better data: You can use newer, more accurate data to retrain your AI. This helps improve performance as the outputs are based on the data being fed into the model.
- Change the way you deploy the model: Sometimes an AI model can struggle to perform well if it isn’t hosted on the right platform or connected to the right hardware.
- Source code enhancement: Some applications are just poorly designed and implemented right from the start. You need to review the source code to make the necessary improvements.
Scale your Generative AI app for a larger audience
Like any other tech solution, AI applications also need to be scalable for future use. Scalability challenges are common in AI app development. For instance, the size of datasets used to train the AI model, the sources used, and the deployment strategy need to be considered.
To make your generative AI app scalable, you need to:
- Ensure that you standardize the development and deployment processes
- Dedicate team efforts to tasks that they know best
- Utilize tools that support creativity, efficiency, and security
- Use development methods that allow updates for the future data
Ethical Considerations and Best Practices
For quite some time now, ethical concerns have been raised against generative AI. The most notable concerns like bias and racism were seen when OpenAI’s ChatGPT was first released. For you generative AI app development, you need to consider the following best practices:
- Bias check: Your AI application needs to be checked for unwanted biases that it may have picked up while training on different datasets.
- Fairness: Your AI model must not discriminate or generate biased outputs that negatively impact different user groups
- Anonymization: You need to take care of data privacy when user data is involved. So its important to anonymize your inputs and outputs at all times
Ensure privacy and security in AI-powered apps
Speaking of privacy, there are also reports of concerns related to data encryption. You need to monitor your app’s performance to identify vulnerabilities. Cyber attackers try to take advantage of the same AI capabilities in a negative way. For this reason, you must never include credentials and tokens in the code.
Apart from data encryption and authentication mechanisms, you must implement ongoing vigilance systems to avoid security breaches.
- Create ethical usage guidelines for your AI app.
- Use techniques like adversarial training to restrict bias
- Routinely monitor your AI app’s performance
- Identify and remove fake content, news, and images.
Best practices for transparent and responsible AI usage
Once the ethical and privacy concerns are addressed, you also need to consider transparency in AI usage. For this purpose, you need to implement the following best practices:
- Documentation: Create detailed descriptions of the AI models’s capabilities, its limitations, and how it is expected to perform.
- Feedback loops: You need to have open channels to discuss and mitigate any concerns and questions arising from stakeholders.
- Anomaly detection: Create systems to identify and take care of unintended behaviours or harmful outputs of the AI app.
- Guidelines and policies: The guidelines and policies for AI use must be updated each time a new feature is added or whenever the AI is retrained.
Navigate legal considerations in AI app development
In today’s day and age, the last thing you would want is a non-compliant AI solution. When it comes to legal considerations, you need to look at the following factors:
Copyrights: Businesses have started to use AI applications to create copyright content. As copyrights only protect content created by humans, this causes legal concerns. You need to ensure that your generative AI app cannot be used to create copyright content.
Confidentiality: Similarly, users and businesses are using AI tools for processes that involve personal information. To avoid legal consequences, you need to ensure that the personal data is either anonymized or used safely.
GDPR compliance: According to the GDPR, you need to define the data subjects and the purpose for gathering data. If you are unable to define the purpose, you cannot proceed with the training of your AI models.
The Future of Generative AI in App Development
AI technologies are developing at an alarming rate. Here is what the future holds for AI-based app development:
Emerging trends and technologies in Generative AI
Based on OpenAI’s latest update called GPT-4 Turbo, the system has two core improvements. One is its ability to ‘pull from a newer database of information’. And the second is its promise ‘to follow instructions better’. This gives us an idea of how fast AI is growing and improving.
AI is already working with features we expected it to perform yesterday. So it’s safe to say that the future is already here. AI can now analyze extensive documents and provide you with a summary. This is because it can now support up to 128,000 tokens of context.
That’s not all, as GPT4 Turbo now also has new API assistants. These are aimed at simplifying the creation of AI-driven apps. You will get capabilities like a Code Interpreter, Retrieval, and improved function calling. For app developers, these features are absolute game-changers.
Predictions for the future impact of Generative AI on app development
According to Forrester, ‘generative AI is accelerating the pace of innovation’. If there is going to be a challenge, its going to be navigating the risks of AI. This is because of the exponential rate at which AI is learning. That said, there is good news too. AI will unlock higher levels of productivity in the years to come.
- By 2026, generative AI design will automate 60% of the design effort for developing new websites and mobile apps.
- By 2027, 15% of applications will be automatically generated by AI without human input.
The same research suggests that by next year,
- ‘40% of enterprise applications will have embedded conversational AI, up from less than 5% in 2020’.
- By 2025 ‘30% of enterprises will have implemented an AI-augmented development and testing strategy, up from 5% in 2021.’
Key Takeaways
In summary, generative AI has tremendous potential to accelerate application development. It suggests code, identifies bugs, and even refactors lines of code. You can command it to write simple applications to speed up app development. Not only that but you can also perform quality checks of your existing code.
Combined with the innovative ideas brought forth by generative AI, you can achieve higher customer satisfaction. The best part is that generative AI applications are built without ever gathering any requirements.
Book your free 40-minute
consultation with us.
Let's have a call and discuss your product.